
I went to ISIT 2016 in Barcelona this year and have decided to write a few posts on some of the talks and papers I saw there. ISIT is a very big conference, and I got to see great work on a variety of topics. Here’s a brief sketch of what I saw on Monday:
After listening to the plenary by Elza Erkip on co-operation in wireless networks, I attended a talk on low rank matrix completion over 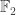


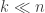
There was also some recent work on integer forcing source coding by He and Nazer. Integer forcing is a technique that was developed for MIMO channels, where instead of decoding all the messages directly, you decode sufficiently many integer-linear combinations of the messages and subsequently compute the individual messages. This is inspired by the compute-and-forward technique of Nazer and Gastpar. The integer forcing idea was used for source coding by Ordentlich and Erez, and He and Nazer gave a successive cancellation generalization this ISIT. They also showed a duality between the successive integer-forcing distributed source coding for Gaussian sources and successive integer-forcing channel coding for the Gaussian MAC.
There was also some interesting work on near-optimal finite length scaling for nonbinary polar codes by Pfister and Urbanke, that I unfortunately missed. They consider 


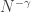
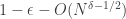
I also attended Oron’s talk (work with Permuter and Pfister) that talked about an upper bound on the feedback capacity of certain channels with state. He talked about unifilar finite-state channels, i.e., finite-state channels where the current state is a time-invariant function of the current input, the current output, and the previous state. They showed that their bound is tight for known unifilar FSCs including the trapdoor channel and the input-constrained BEC.
I had one of my talks on Monday, on secret key generation from correlated Gaussian sources. We gave a polynomial-time scheme using nested lattice codes for secret key generation in a multiterminal source model. My talk slides can be found here. We used lattice quantizers to reduce the problem to that of SK generation over discrete alphabets and then used standard techniques of information reconciliation and linear SK generation. We also used ideas from concatenated coding for ensuring that the overall computational complexity is polynomial in the number of samples.
There were other interesting talks in my session as well. He, Luo and Cai had a paper on the strong secrecy capacity of the wiretap II channel where the main channel is a DMC. This is a setting where the eavesdropper can observe any arbitrary subsequence (of a certain fixed length) of the output of the main channel, and the objective is to guarantee strong secrecy. They showed that if the eavesdropper can observe an 
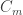
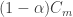
The last session that I attended was on entropy. Kamath and Verdu had an interesting paper on estimating Shannon and Renyi entropy rates of DTMCs. They studied certain plug-in estimators, and gave some guarantees on the convergence of the estimator. Ordentlich had a paper on lower bounds on the entropy rate of binary HMMs.
Other papers that sounded interesting to me: A paper on a generalization of approximate message passing by Fletcher, Ardakan, Rangan and Schnieter got me curious. I have to look up this AMP stuff sometime. Reeves and Pfister had some Replica-symmetry based methods for compressive sensing. There was also a paper on duplication distance of binary strings by Alon, Bruck and Jain. Deshpande, Abbe and Montanari have a paper on an information theoretic view of the binary stochastic block model, which is used widely in problems such as community detection. Rush and Venkataramanan had a paper on finite sample analysis of AMP, that also looks interesting.
 identical items (in this case, cars) in our inventory. Several customers arrive at the store to rent these items for specified durations of time. Customer
identical items (in this case, cars) in our inventory. Several customers arrive at the store to rent these items for specified durations of time. Customer  arrives at time
arrives at time 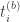 (booking time) and requests an item for the duration
(booking time) and requests an item for the duration 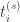 (the start time) to
(the start time) to 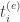 (end time). Note that
(end time). Note that 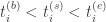 . The problem now is to decide which bookings can be satisfied, and how one can allot the various items to the users. Customer
. The problem now is to decide which bookings can be satisfied, and how one can allot the various items to the users. Customer 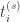 . Each booking is associated a certain revenue depending on the duration for which it is booked. For example, a customer booking an item for 2 hours may have to pay more money per hour than a customer booking for a day (discounts for longer durations). To make matters worse, the
. Each booking is associated a certain revenue depending on the duration for which it is booked. For example, a customer booking an item for 2 hours may have to pay more money per hour than a customer booking for a day (discounts for longer durations). To make matters worse, the  is available from 1 pm to 5 pm, and item
is available from 1 pm to 5 pm, and item  is available from 3 pm to 9 pm. If we only list the number of items, we see that one item is available from 1 pm to 3 pm, two are available from 3 pm to 5 pm, and one available from 5 pm to 9 pm. Let us now imagine that a user wants an item from 2 pm to 6 pm. We see that the number of items available for this duration is atleast one. However, this request cannot be catered to since no single item is available from 2-6 pm.
is available from 3 pm to 9 pm. If we only list the number of items, we see that one item is available from 1 pm to 3 pm, two are available from 3 pm to 5 pm, and one available from 5 pm to 9 pm. Let us now imagine that a user wants an item from 2 pm to 6 pm. We see that the number of items available for this duration is atleast one. However, this request cannot be catered to since no single item is available from 2-6 pm.

 and
and 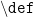 .
. but before
but before  .
. to denote a quantity. You can define a command like
to denote a quantity. You can define a command like
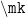 . Note that you can use this only in the math mode and LaTeX will give you an error if you use it in the normal mode. However, this can be solved using the
. Note that you can use this only in the math mode and LaTeX will give you an error if you use it in the normal mode. However, this can be solved using the  command. Use
command. Use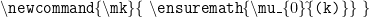

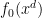 . You can define a user defined command of the form
. You can define a user defined command of the form
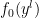 . You don’t have to define a new command. Instead, you can specify arguments in the following manner:
. You don’t have to define a new command. Instead, you can specify arguments in the following manner:![{\backslash \texttt{newcommand} \{ \backslash \texttt{fx} \}[2]\{ \texttt{f} \_ \{\texttt{0}\}(\# \texttt{1} \hat{}\: \{\# \texttt{2}\}) \} }](https://s0.wp.com/latex.php?latex=%7B%5Cbackslash+%5Ctexttt%7Bnewcommand%7D+%5C%7B+%5Cbackslash+%5Ctexttt%7Bfx%7D+%5C%7D%5B2%5D%5C%7B+%5Ctexttt%7Bf%7D+%5C_+%5C%7B%5Ctexttt%7B0%7D%5C%7D%28%5C%23+%5Ctexttt%7B1%7D+%5Chat%7B%7D%5C%3A+%5C%7B%5C%23+%5Ctexttt%7B2%7D%5C%7D%29+%5C%7D+%7D&bg=ffffff&fg=000000&s=0&c=20201002)
 ,
,  represent the two arguments. When you want to use the same in an equation, simply use
represent the two arguments. When you want to use the same in an equation, simply use 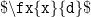 to get
to get 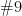 .
.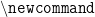 will give an error whereas
will give an error whereas 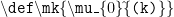

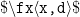 .
.